Compute Nodes¶
Perun is a cluster of compute nodes named cn[001-060] and gn[001-076]. The nodes are
equipped with x86-64 architecture AMD EPYC processors (universal
and cloud partitions) and NVIDIA Grace Hopper Superchips
(accelerated partition). The system is built on the BullSequana
XH3000 architecture and contains three types of compute nodes.
| Nodes | Moda / Cnt | Cores | Memory | Diskb | GPUs | Network |
|---|---|---|---|---|---|---|
| cn[001-045] | U / 45 | 320 | 1152 GB | 3.8 TB | none | NDR200 |
| cn[046-060] | C / 15 | 320 | 2304 GB | 7.6 TB | none | NDR200 |
| gn[001-076] | A / 76 | 288 | 480 GB LPDDR + 384 GB HBM | 3.8 TB | 4× GH200 | 4× NDR400 |
a U - universal module, C - cloud module, A - accelerated module.
b The value represents raw local NVMe capacity.
Universal module nodes¶


The universal partition consists of 45 compute nodes implemented as BullSequana XH3420 blades. Each blade is a 1U hot-plug module hosting three independent dual-socket nodes. The nodes are based on AMD EPYC Turin 9845 processors (Zen 5 / Zen 5c architecture) using the SP5 platform with 12 DDR5 memory channels per socket. Cooling is provided by direct liquid cooling (DLC) using cold-plate technology.
| Feature | cn[001-045] |
|---|---|
| Processor | 2× AMD EPYC Turin 9845 (160 cores per CPU) |
| Architecture | Zen 5 / Zen 5c, SP5 |
| Memory | 1152 GB DDR5 @ 5600 MT/s |
| Local Storage | 3.8 TB NVMe |
| Interconnect | 200 Gb/s InfiniBand NDR |
Cloud module nodes¶
The cloud partition consists of 15 nodes based on the same BullSequana XH3420 hardware platform and AMD EPYC Turin 9845 processors as the universal nodes. The primary difference is increased memory capacity and local storage, making it ideal for cloud infrastructure.
| Feature | cn[046-060] |
|---|---|
| Processor | 2× AMD EPYC Turin 9845 (160 cores per CPU) |
| Architecture | Zen 5c |
| Memory | 2304 GB DDR5 @ 5600 MT/s |
| Local Storage | 7.6 TB NVMe |
| Interconnect | 200 Gb/s InfiniBand NDR |
Accelerated module nodes¶
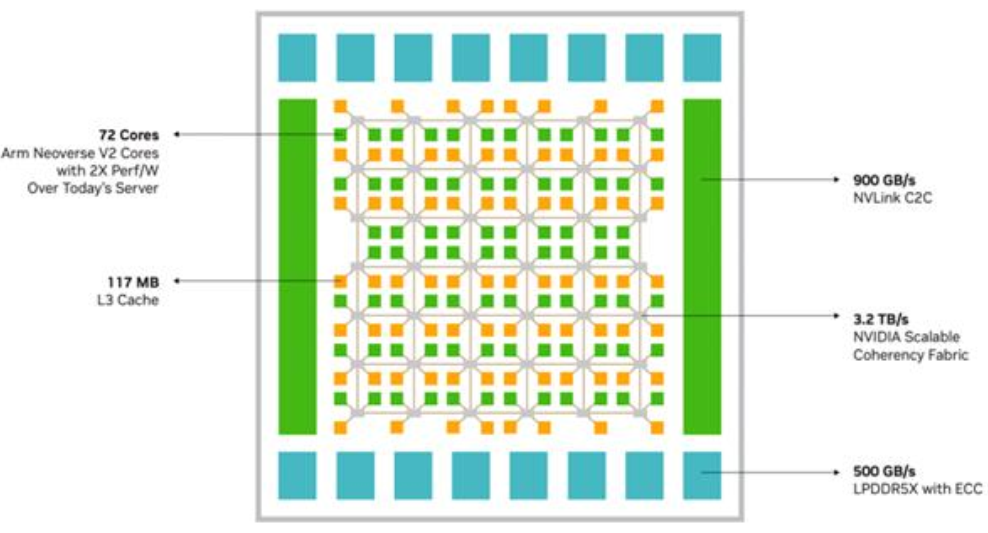
Fig. 2: NVIDIA Grace architecture.
| Feature | gn[001-076] |
|---|---|
| Superchips | 4× NVIDIA Grace Hopper GH200 |
| CPU | 4× 72-core Arm Neoverse V2 (Grace) |
| GPU | 4× Hopper GPU, 96 GB HBM3 each |
| Memory | 480 GB LPDDR5X (CPU) + 384 GB HBM3 (GPU) |
| Local Storage | 3.8 TB NVMe |
| Interconnect | 4× 400 Gb/s InfiniBand NDR |
Processors¶
AMD Turin 9845¶

Fig. 3: AMD Turin architecture.
| AMD EPYC Turin 9845 | |||
|---|---|---|---|
| Architecture | x86-64 (Zen 5 / Zen 5c) | Process | 4 nm (TSMC) |
| Cores | 160 | Threads | 320 (SMT2) |
| Base Frequency | 2.10 GHz | Max Boost Frequency | up to 3.70 GHz |
| Memory Channels | 9 TB @ DDR5-6000a | TDP | 400 W |
a Maximum capacity depends on DIMM type (e.g., 3DS DIMMs).
Arm Neoverse V2¶
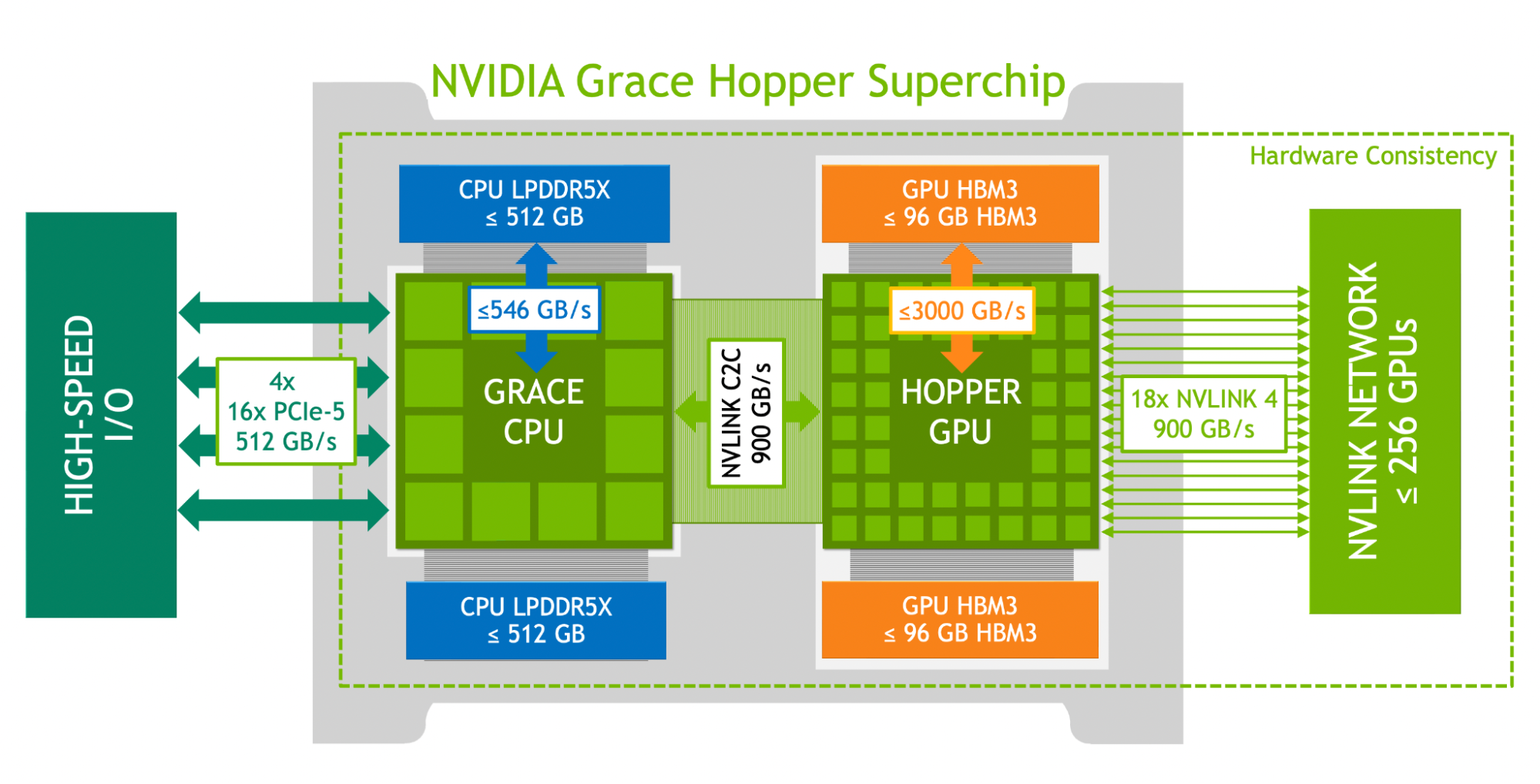
NVIDIA Grace is a 64-bit Arm-based server processor designed for tightly coupled HPC and AI systems. It is built around the Arm Neoverse V2 microarchitecture implementing the Armv9.0-A instruction set and is integrated within the Grace Hopper GH200 Superchip.
Each Grace CPU contains 72 high-performance Arm cores and is paired with LPDDR5X memory delivering up to 546 GB/s memory bandwidth per processor. The architecture supports Scalable Vector Extension v2 (SVE2) and Advanced SIMD (NEON), enabling efficient vectorized scientific computing.
Grace implements Large System Extensions (LSE) for efficient atomic operations and supports hardware virtualization, memory encryption, and advanced reliability features. Within the GH200 Superchip, the Grace CPU is coherently connected to the Hopper GPU via NVLink-C2C with up to 900 GB/s bidirectional bandwidth, enabling unified high-bandwidth CPU–GPU memory access.
The processor is optimized for hybrid CPU–GPU workloads, AI training and inference, and large-scale HPC applications requiring high memory throughput and strong energy efficiency.
| Arm Neoverse V2 | |||
|---|---|---|---|
| Architecture | Armv9.0-A | Process | 4 nm (TSMC) |
| Cores | 72 | Threads | 72 (no SMT) |
| Base Frequency | 2.60 GHz | Max Boost Frequency | 3.50 GHz |
| Memory Channels | 456 GB @ LPDDR5Xa | TDP | 500 W |
a Maximum capacity depends on DIMM type.
Accelerators¶
NVIDIA Hopper GPU (GH200)¶
The NVIDIA Hopper GPU used in the accelerated partition is part of the Grace Hopper GH200 Superchip. Hopper is the ninth generation NVIDIA data-center GPU architecture and is designed for large-scale HPC and AI workloads requiring extreme floating-point throughput and memory bandwidth.
The GPU integrates high-performance Streaming Multiprocessors (SMs) with fourth-generation Tensor Cores supporting a broad range of precisions, including FP64, FP32, TF32, FP16, BF16, FP8, and INT8. This allows efficient execution of both traditional double-precision scientific simulations and modern mixed-precision AI workloads.
Each Hopper GPU in the GH200 configuration is equipped with 96 GB of HBM3 memory providing up to approximately 4 TB/s of memory bandwidth. The memory subsystem supports SECDED ECC protection and includes row remapping mechanisms for improved reliability.
Hopper introduces several architectural enhancements compared to the previous Ampere generation:
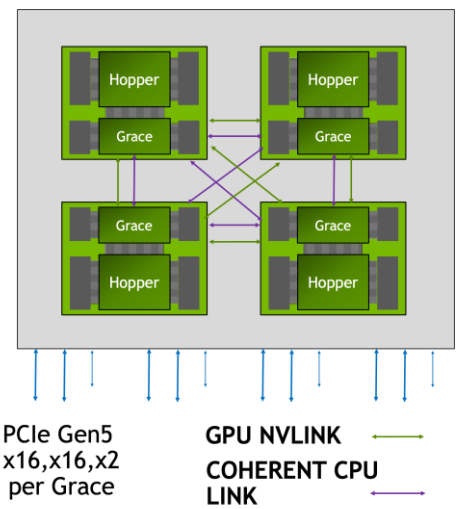
Fig. 5: Grace Hopper interconnection.
- Increased FP64 and FP32 throughput
- Fourth-generation Tensor Cores
- DPX instructions accelerating dynamic programming algorithms
- 50 MB L2 cache for improved data locality
- Asynchronous execution engines and Tensor Memory Accelerator (TMA)
- Second-generation Multi-Instance GPU (MIG)
Within a 4-way GH200 node, Hopper GPUs are interconnected using high-bandwidth NVLink peer-to-peer links. Each GPU can communicate directly with its peers, enabling high aggregate bandwidth for multi-GPU parallel workloads.
The Hopper GPU is optimized for:
- Large-scale AI model training and inference
- Hybrid CPU–GPU scientific workflows
- Data-intensive workloads requiring extreme memory bandwidth
In the Grace Hopper configuration, the GPU is coherently connected to the Grace CPU via NVLink-C2C, enabling unified memory semantics and high-bandwidth CPU–GPU data exchange far beyond traditional PCIe-based accelerator systems.
| NVIDIA Hopper GPU (GH200) | |||
|---|---|---|---|
| Architecture | NVIDIA Hopper | GPU Generation | 9th (Data Center) |
| CUDA Cores | 16,896a | Tensor Cores | 4th Generation |
| FP64 Performance | up to ~34 TFLOP/sa | FP32 Performance | up to ~67 TFLOP/sa |
| GPU Memory | 96 GB HBM3 | Memory Bandwidth | up to ~3.6–4.0 TB/s |
| NVLink (GPU-GPU) | up to 900 GB/s aggregate | TDP | 1000 W |
a Exact values depend on specific Hopper SKU configuration within GH200.